概述
Kafka是一个高吞吐、分布式、基于发布订阅的消息系统,利用Kafka技术可以在廉价的PC Server上搭建起大规模消息系统。
应用场景
Kafka具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性,适用于离线和在线的消息消费,如常规的消息收集、网站活性跟踪、聚合统计系统运营数据(监控数据)、日志收集等大量数据的互联网服务的数据收集场景。
- 日志收集(filebeat): 收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如Hadoop、Hbase、Solr等;
- 消息系统: 解耦生产者和消费者、缓存消息(kafka缓存7天)
- 运营指标: 记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
- 流式处理:比如spark streaming和storm;
kafka 架构 和 基本概念
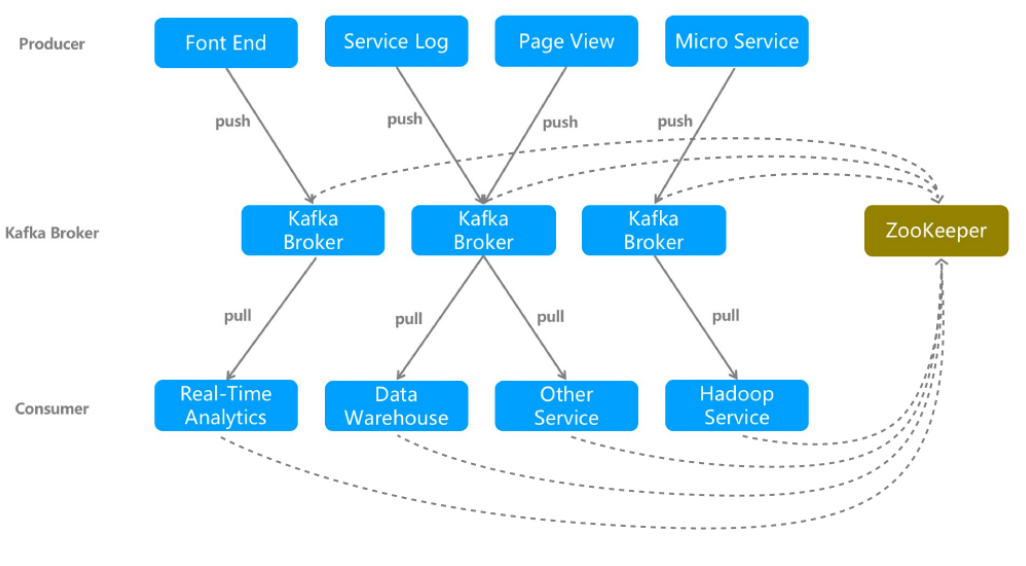
- Broker:Kafka集群中的实例,这些服务实例被称为Broker。是Kafka当中具体处理数据的单元。Kafka支持Broker的水平扩展。一般Broker数据越多,集群的吞吐力就越强。
- Topic:topic的存放形式,每一个topic都可以设置partition数量。partition的数量决定了log的数量。producer 在生产消息时,会把消息发布到topic的各个partition中。上面说的副本都是以partition为单位的,不过只有一个partition的副本会被选为leader作为读写用。
- Partition:Kafka将Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件下存储这个Partition的所有消息。
- Producer:负责发布消息到Kafka Broker。
- Consumer:消息消费者,从Kafka Broker读取消息的客户端。
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指
定group name)。
- ZooKeeper:kafka与Zookeeper级联,通过Zookeeper管理级联配置,选举Leader。
kafka 相关操作
1 | //查看topics |
< — 待续 — >