redis
redis 五大数据类型
- string //最大为512M
- hash
- list // 按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边),它的底层实际上是个链表。
- set //string 类型的无序集合。
zset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//String基本操作
set {key} {value} [EX seconds] [PX milliseconds]
get {key}
//multi-
mset {key} {value} {key} {value} //原子操作
mget {key} {key}
//设置过期时间的key, key对应的value存在时,则覆盖
setex {key} seconds {value}
//key不存在时写入value,key存在则不做操作
setnx {key} {value}
del {key}
//对数字的基本操作
set {key} {value} //value must be int
incr {key} //value + 1
decr {key} //vlaue - 1
incrby {key} {incrment} //value + incrment
decrby {key} {incrment} //value - incrment1
2
3
4
5
6//redis hash: 形式 {key} { {key}:{value} }
HSET {key} {field} {value}
HGET {key} {field}
HDEL {key} {field}
HKEYS {key}
HVALS {key}
Redis底层主要的数据结构:
- 动态字符串(SDS)
- 双端链表(Link)
- 字典
- 压缩列表
- 整数集合
1 | //SDS |
1 | //双端链表 |
redis之map
1 | //字典使用hash表作为底层实现 |
redis map结构图:
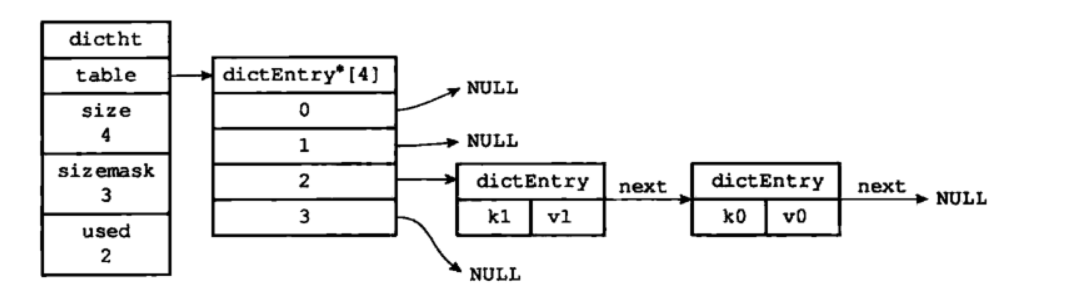
存储流程:
1.计算hash值
a. hash = dict->type->hashFunction(key); //计算key的hash值
//使用哈希表的sizemask属性和第一步得到的哈希值,计算索引值
b. index = hash & dict->ht[x].sizemask;
2.解决hash冲突:
a. 链地址法。通过字典里面的 next 指针指向下一个具有相同索引值的哈希表节点。
3.扩容和收缩:当哈希表保存的键值对太多或者太少时,就要通过rerehash(重新散列)来对哈希表进行相应的扩展或者收缩
a.执行扩展操作,会基于原哈希表创建一个大小等于 ht[0].used2n 的哈希表
b.利用上面的哈希算法,计算索引值,然后将键值对放到新的哈希表位置上。
c.所有键值对都迁徙完毕后,释放原哈希表的内存空间。
- 触发扩容的条件:
a. 没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于1。
b. 正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于5。负载因子 = 哈希表已保存节点数量 / 哈希表大小。
- 渐近式 rehash
什么叫渐进式 rehash?也就是说扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。所以Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行 增加操作,一定是在新的哈希表上进行的。
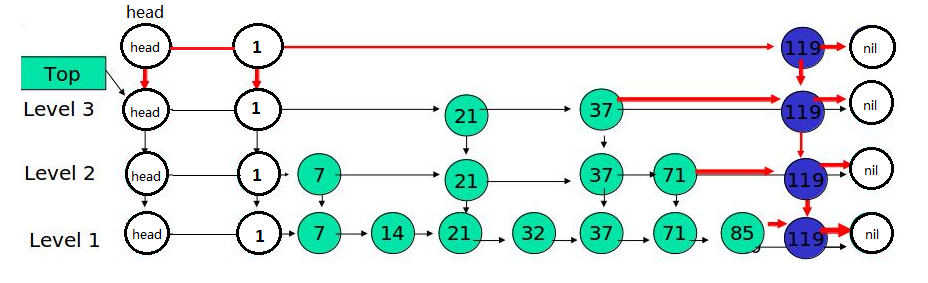
跳表(skip-list)
跳跃表(skip-list)是一种有序数据结构,通过在每个节点中维持多个指向其它节点的指针,从而到达快速访问节点的目的,具有如下性质:
1.多层组成
2.每层都是有序链表,至少包含两个节点(head,tail)
3.最底层的链表包含了所有的元素
4.如果一个元素出现在某一层链表中,那么在该层之下的链表中也全都会出现
(上一层的元素是当前层的元素的子集)
5.一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;
redis skip-list结构图:
1 | //redis中跳表节点定义 |
1.查找:从最高层的链表节点开始,如果比当前节点要大和比当前层的下一个节点要小,那么则往下找,也就是和当前层的下一层的节点的下一个节点进行比较,以此类推,一直找到最底层的最后一个节点,如果找到则返回,反之则返回空。
2.插入:首先通过随机数来确定插入的层数k, 将新元素插入到从底层到k层;
3.删除:先查找到指定节点,然后将节点从链表中删除即可,如果删除以后只剩下头尾两个节点,则删除这一层;
整数集合(intset)
整数集合(intset)是redis用来保存整数数值的集合抽象数据类型(int16_t, int32_t, int64_t)的整数值,保证集合中不会出现重复元素;
typedef struct inset{
uint32_t encoding; //编码方式
uint32_t length; //集合包含的元素数量
int8_t contents[];
}inset
1.整数集合的每个元素都是 contents 数组的一个数据项,它们按照从小到大的顺序排列,并且不包含任何重复项。
2.length 属性记录了contents 数组的大小
3.需要注意:虽然 contents 数组声明为 int8_t 类型,但是实际上contents 数组并不保存任何 int8_t 类型的值,其真正类型有 encoding 来决定
升级
当我们新增的元素类型比原集合元素类型的长度要大时,需要对整数集合进行升级,才能将新元素放入整数集合中。具体步骤:
1、根据新元素类型,扩展整数集合底层数组的大小,并为新元素分配空间。
2、将底层数组现有的所有元素都转成与新元素相同类型的元素,并将转换后的元素放到正确的位置,放置过程中,维持整个元素顺序都是有序的。
3、将新元素添加到整数集合中(保证有序)。
升级能极大地节省内存。
降级
整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。
压缩列表
Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,
一个压缩列表可以包含任意多个节点(entry),一个节点可以保存一个字节数组或者一个整数值
压缩列表的原理:压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存
应用场景
- string: userid映射用户信息
- hash: 角色信息/装备道具
- list: 消息队列、评论
- set: 属性记录、资格
- zset: 排行榜
- ttl: 活动礼包,Cache过期等